
AI Chatbot for Smarter Website Engagement
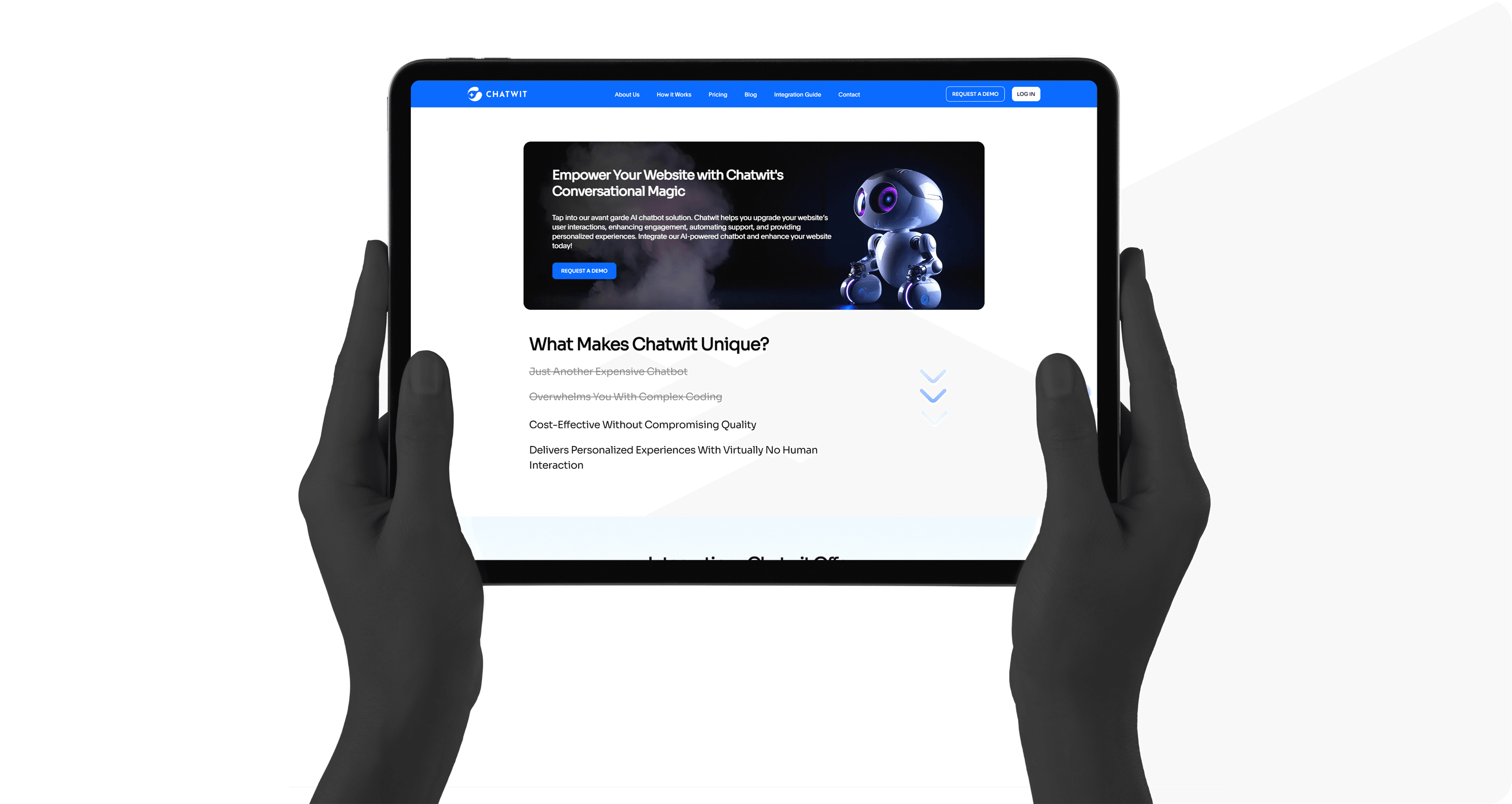
Project Overview
Industry : Technology, Information and Internet
Location : Ahmedabad
Year : 2023
Technologies Used
RAG Pipeline
AI Chatbot
LLM Integration
AI Backend
Node.js
React Native
Django REST Framework
PostgreSQL
Express.js
Challenges
Dynamic website scraping failed on JavaScript heavy pages causing incomplete data extraction. Embedding generation overloaded CPU during high volume processing without GPU acceleration. FAISS vector store queries slowed down as database grew beyond 1M embeddings. RAG pipeline latency spikes broke real-time chat responsiveness under concurrent users.
- Puppeteer timeouts and anti-bot detection blocking 30% of scrape attempts.
- Transformer models (BERT) memory exhaustion during batch embedding jobs.
- Vector search accuracy dropped with noisy scraped data; irrelevant responses.
- GPT-4 API rate limits and costs exploding during peak query volumes.
Solutions
1. DYNAMIC SCRAPING OPTIMIZATION
Traditional scraping pipelines were failing against modern anti-bot systems, resulting in low success rates. Implemented a hybrid Puppeteer + Playwright architecture with stealth plugins, along with retry logic and proxy rotation. This increased scraping reliability from 70% to 98% across protected targets.
2. EMBEDDING ACCELERATION
Embedding generation using BERT and Sentence Transformers was too slow for production workloads. Migrated to GPU-accelerated inference using ONNX Runtime and introduced batch processing queues. Reduced embedding latency from 5 seconds to 500 milliseconds per document, significantly improving throughput.
3. RAG PIPELINE EFFICIENCY
High LLM usage costs and latency were impacting scalability. Implemented LangChain caching and query rewriting to reduce redundant GPT-4 calls by 60%. Additionally, introduced async processing using BullMQ to decouple retrieval from generation, ensuring real-time response performance.
Results
Achieved 98% scraping success rate with hybrid Puppeteer/Playwright setup bypassing anti-bot measures across dynamic sites. Reduced embedding generation time from 5s to 500ms per document using GPU accelerated ONNX inference and batch queues. Scaled FAISS to handle 10M+ embeddings with sub 50ms query latency via sharded HNSW indexing and periodic reindexing. Delivered real-time RAG responses under 1s end-to-end by cutting GPT 4 calls 60% through LangChain caching, async BullMQ processing, and distilled models boosting concurrent users from 500 to 5,000 while slashing API costs 70%. Overall system accuracy hit 92% with 4x embedding compression maintaining response relevance for production chatbot deployment.